1/ Systèmes distribué.
Dans
le jargon informatique définir un système
distribué peut avoir plusieurs définitions possibles. Une définition
parmi
d'autres : un système distribué est un groupe d'ordinateurs indépendants
connectés en réseau et la communication entre les différent entités se
fait à travers se dernier. Ce groupe apparaît du point de vue de
l'utilisateur comme
une unique entité. La communication entre ce groupe d'ordinateurs a pour
fin de
réaliser un but commun.
Un système distribué peut être composé de point de
vue architecture matérielle par : Un ordinateurs standards connectés en réseau,
une machine multiprocesseurs avec mémoire partagée ou Cluster d'ordinateurs
dédiés au calcul/traitement massif parallèle. En ce qui concerne le coté
logicielle d'un système distribué est composé de plusieurs logiciels s'exécutant
indépendamment et en parallèle sur un ensemble d'ordinateurs connectés en
réseau.
Avantages :
- partage de données
- partage de données
- partage de périphériques
- communication
- souplesse (politiques de placements)
- souplesse (politiques de placements)
- la transparence(d'accès, concurrence, réplication)
Inconvénients :
- logiciels : peu de logiciels disponibles
- réseaux : la saturation et délais (panne)
- sécurité : piratage
- logiciels : peu de logiciels disponibles
- réseaux : la saturation et délais (panne)
- sécurité : piratage
2/ Exemples
2.1 Serveur de fichiers.
Un serveur de fichiers permet de partager des données à travers un
réseau. En effet il établit une relation entre un poste jouant le
rôle de serveur et plusieurs autres postes des différents utilisateurs
du type client. Ce lien est une relation du type partage de données. Le
terme “serveur de fichier” désigne en fait le dispositif qui a été mis
en place pour héberger le système exécutif.
En plus il permet l'accès aux fichiers de l'utilisateur quel que soit
la machine utilisée. Les fichiers d'un utilisateur se trouvent uniquement sur
le serveur mais ce dernier à la possibilité d'accéder à ces fichiers à partir
de n'importe quelle machine cliente.
 Figure 1 : Serveur de fichier
Figure 1 : Serveur de fichier
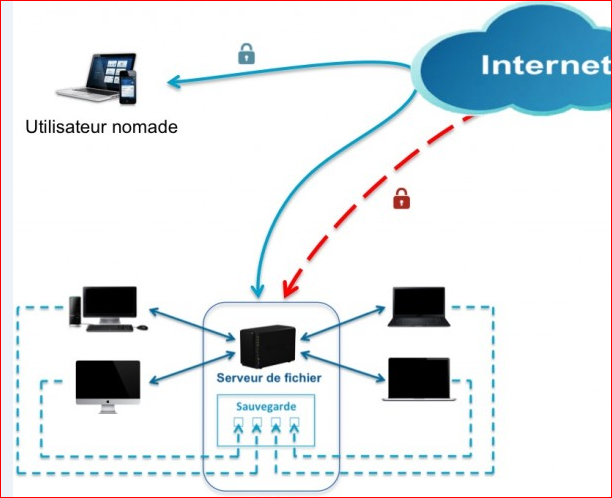
La
figure ci-dessus montre le fonctionnement d'un serveur de fichier.En
effet, ce type de serveur est doté d'une grande capacité de stockage sur
son espace disque, permettant le stockage des fichiers utilisateurs.
Par ailleur, un utilisateur lambda connecté au réseau peut récupérer un
ou plusieurs fichiers grâce à un protocole. Il existe quatre protocoles
répandus pour ce type de partage en réseau :
- FTP (File Transfert Protocol)
- CIFS (Common Internet File System)
- NFS (Network File System)
- NCP (Netware Core Protocol).
- FTP (File Transfert Protocol)
- CIFS (Common Internet File System)
- NFS (Network File System)
- NCP (Netware Core Protocol).
Le
choix du protocole se définit en fonction de l’utilité du serveur,
ainsi que du système d’exploitation utilisé. Les utilisateurs du
Microsoft Windows utilisent le protocole CIFS, par contre ceux qui
utilisent UNIX utilisent le protocole NFS. Le protocole FTP est aussi
très utilisé lorsqu’un utilisateur n’a pas besoin d’avoir une connexion
permanente établie entre le serveur et son poste, on parle de connexion
ponctuelle.
Ce
genre de serveur informatique représente beaucoup d’avantages, mais
aussi quelques inconvénients. En effet, la capacité d'accéder aux
fichiers à partir de n'importe quelle machine représente un grand atout
pour ce type de serveur. Le
système de sauvegarde est associé à ce serveur et la transparence pour
l'utilisateur. Ce pendant, pour les inconvénients si le réseau ou le
serveur tombe en panne l'accès aux
fichiers est perdu.
2.2 Serveur web.
Un serveur web est un autre exemple de système
distribué auquel se connecte un nombre quelconque de navigateurs web (clients).
Il permet l'accès à distance à des sites web (exemple de serveur web Apache,
Nginx...). Par ailleurs, il y a deux types de traitements faites par un tel serveur
soit un traitement simple dans ce cas le serveur renvoie une page HTML statique
qu'il stocke localement, ou bien un traitement plus complexe le serveur
interroge une base de données pour générer dynamiquement le contenu d'une page
web. Pour un utilisateur, les informations s'affichent dans son navigateur quel
que soit la façon dont le serveur les génère.

Figure 2. Communication client-serveur web en http
La figure au-dessus
illustre la communication entre un client et un serveur web. Tout d’abord, un
client se connecte au serveur. Ensuite, Le client formule une requête HTTP au
serveur. En fin, le serveur répond à la requête : soit par un document (page
web, image etc.) par tout moyen, soit en indiquant qu'il y a erreur
(formulation incorrecte de la requête ou données non disponibles). L'échange
reprend à l'étape 2 ou se termine (et peut ensuite reprendre à l'étape 1).
Référence :
[1] http://delmas-rigoutsos.nom.fr/documents/YDelmas-ArchiWeb/YDelmas-ArchiWeb.html
[2] https://fr.wikipedia.org/wiki/Calcul_distribu%C3%A9
[3] https://www.over-blog.com/Quest_ce_quun_serveur_de_fichier-1095203942-art152998.html